
Posted on September 15, 2015
UW CSE P576 notes – Harris corner detection
The following are my notes on the Harris corner detection algorithm for finding the features in an image. These slide screenshots were taken from the University of Washington course homepage here:
http://courses.cs.washington.edu/courses/csep576/15sp/projects/project1/web/project1.htm
The idea is to consider a small window around each pixel p in an image. We want to identify all such pixel windows that are unique. Uniqueness can be measured by shifting each window by a small amount in a given direction and measuring the amount of change that occurs in the pixel values.
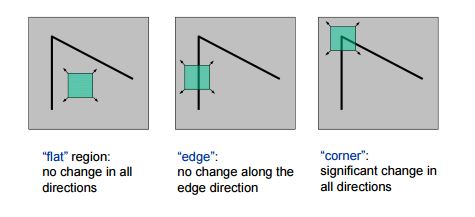
More formally, we take the sum squared difference (SSD) of the pixel values before and after the shift, and identifying pixel windows where the SSD is large for shifts in all 8 directions. Let us define the change function E(u,v) as the sum of all the sum squared differences (SSD), where u,v are the x,y coordinates of every pixel in our 3 x 3 window and I is the intensity value of the pixel. The features in the image are all pixels that have large values of E(u,v), as defined by some threshold.
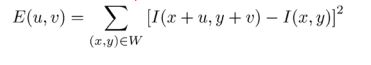
After some fancy math that is best left explained by Wikipedia or the original slides which essentially involve taking the first order approximation of the Taylor series expansion for I(x + u, y + v), we are left with:
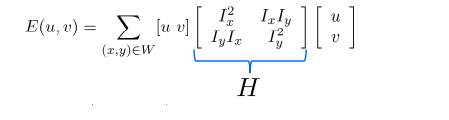
where H is the Harris matrix and the I_x and I_y terms are the gradients in the x and y directions, respectively (the gradient values for each pixel can be done using the Sobel operator). Note that this is a sum of all the matrices in the window W. This is important later.
Remember that we want the SSD to be large in shifts for all eight directions, or conversely, for the SSD to be small for none of the directions. By solving for the eigenvectors of H, we can obtain the directions for both the largest and smallest increases in SSD. The corresponding eigenvalues give us the actual value amount of these increases. Because H is a 2×2 matrix, solving for the eigenvalues can be done by taking the determinant and setting it to 0, and using the quadratic equation to find the two possible solutions.
Because solving the quadratic equation for every pixel is computationally expensive (it requires the square root operator), we can use a variant where instead of solving for the eigenvalues directly, we compute a corner strength function as defined by:
c(H) = determinant(H) / trace(H) where the trace is the sum of the two elements in the main diagonal (upper left to lower right). This is the Harris operator.
One question that tripped me up as well as other students is why the determinant of the Harris matrix isn’t always equal to zero. The determinant of H at first glance is equal to
I_x^2 * I_y^2 – I_x*I_y * I_x * I_y. This becomes I_x^2 * I_y^2 – I_x^2 * I_y^2 = 0. However, as previously noted, these individual terms represent the sums across all the pixel values in the window. So I_x^2 is summed up over all the pixels in the window W, as is I_x*I_y and such.
Here then is the high level pseudocode:
1. Take the grayscale of the original image
2. Apply a Gaussian filter to smooth out any noise
3. Apply sobel operator to find the x and y gradient values for every pixel in the grayscale image
4. For each pixel p in the grayscale image, consider a 3×3 window around it and compute the corner strength function. Call this its Harris value.
5. Find all pixels that exceed a certain threshold and are the local maxima within a certain window (to prevent redundant dupes of features)
6. For each pixel that meets the criteria in 5, compute a feature descriptor.
Step 5 is itself a topic of much discussion that is out of scope for these notes. The simplest approach is to use a 5 x 5 window. In terms of feature matching, such a feature descriptor is invariant to translation, but nothing else. Better feature descriptors would be invariant to rotation, illumination, and scaling.